Installering av lokal språkmodell
Innhold
1. Om lokale språkmodeller.
Et problem med tjenester som ChatGPT, er at de kjører på noen andres datamaskin.
For eksempel med ChatGPT er at det er sensurert, og koster penger å bruke.
Ved å kjøre en modell lokalt så kan man ha full kontroll over hva som skjer, men hovedsakelig så gjør man det for erfaringen, og fordi det er gratis.
2. Nødvendige spesifikasjoner.
llama.cpp, «motoren» som kjører språkmodellen, kan kjøre på alt fra en Raspberry Pi, til en svær server.
Forskjellen er kvaliteten på modellen man kjører.
2.1. 1B
Dette kunne ha kjørt på en Raspberry Pi 4, men er veldig dårlig til det de fleste bruker en språkmodell til.
2.2. 7B
Dette kjører med en tålig god fart på min laptop med en i3-prosessor. Dette bruker ca. 8GB med RAM.
På min stasjonære PC med en Ryzen 7 2700X og en RTX 2070, så genererer denne størrelsen modell tekst nærmest ummidelbart. Hele modellen får plass på skjermkortet.
2.3. 13B
Dette kjører greit på min Ryzen 7 2700X og RTX 2070, jeg klarer å få 12 ut av 34 lag over på skjermkortet. Denne modellen bruker ca. 16GB med RAM.
Denne størrelsen gir gode svar, men av og til rart formulert. Logikken kunne ha vært bedre.
2.4. 30B
Denne størrelsen kjører så vidt på min Ryzen 7 2700X og RTX 2070. Jeg får flyttet 8 lag over til skjermkortet mitt. Moddelen bruker ca. 25GB med RAM.
Denne modellen gir veldig gode svar og skriver veldig naturlig.
2.5. 70B
Denne størrelsen er for stor for at jeg kan teste den ut.
3. Installasjon av Oobabooga sin text-generation-webui
3.1. Hent text-generation-webui
3.1.1. Klon repoet
Det mest anbefalte er å klone repoet, da kan man lett oppdatere når det kommer en oppdatering. Dette krever at Git er installert.
Åpne terminalen på Linux, eller Git Bash på Windows. Skriv inn:
git clone https://github.com/oobabooga/text-generation-webui.git
3.1.2. Last ned ZIP-fil.
Om det er vanskelig å få Git til å fungere, gå til https://github.com/oobabooga/text-generation-webui og trykk påCode->Download zip. Så pakk ut ZIP-filen til et sted man finner det igjen.
3.2. Start opp text-generation-webui
3.2.1. Linux
Åpne terminalen og navigér til der repoet ble klonet til. Så kjør:
./start_linux.sh
Om man får:
ikke tilgang: ./start_linux.sh
Så må man tillate filen å kunne kjøres. Dette kan gjøres ved å kjøre:
chmod +x start_linux.sh
Programmet vil så lede igjennom forskjellige valg, svar så på spørsmålene.
Etter det, så går man inn på http://127.0.0.1:7860 i nettleseren.
3.2.2. Windows
Åpne filutforsker (WIN+E) og navigér til der repoet ligger.
Dobbeltklikk så på start_windows.bat.
Svar så på spørsmålene som kommer opp.
Om dette ikke fungerer så kan man åpne PowerShell eller Windows Terminal, navigere til text-generation-webui, og så kjøre start_windows.bat ved å bruke
.\start_windows.bat
Åpne så http://127.0.0.1:7860 i nettleseren.
4. Valg av språkmodell.
Fordelen med å kjøre modellene lokalt, er at man kan fritt frem velge hvilken språkmodell man ønsker å bruke.
text-generation-webui bruker GGUF-filer.
4.1. Laste ned modeller.
Her er en liste av modeller:
4.1.1. Llama 2
Llama 2 oppleves best for generell tekstgenerering. Den har blitt utviklet av Meta (Facebook).
4.1.2. ToRA
Denne modellen er utviklet av Microsoft. Denne oppleves best for matte.
4.2. Legg inn modellen i text-generation-webui
Flytt GGUF-filen til text-generation-webui/models/
4.3. Aktivér modellen
Aktivér modellen ved å gå inn på webui-et, (127.0.0.1:7860), så gå til fanen ved navnet Model.
Velg modellen som ønsket brukt fra listen, så velg llama.cpp som Model loader.
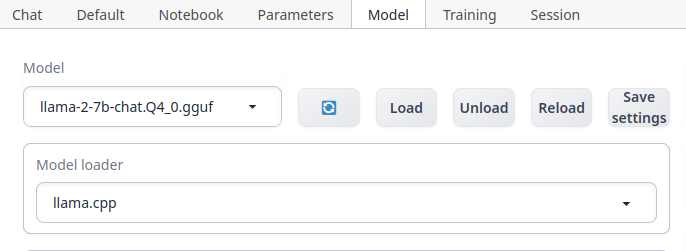
Velg så Load.
5. Konfigurering
5.1. Bruk av skjermkort
Man kan laste opp deler av modellen over på skjermkortet, hvor mye kommer an på mengde VRAM på skjermkortet.
For å gjøre dette, går man inn på Model og endrer på n-gpu-layers.
6. Kontakt:
Foreslag for endringer kan sendes til: kimandre+spraakmodell@bjorkede.no